
Reinforcement learning, an area of machine learning, might be most commonly known in relation to autonomous vehicles: where a car learns how to drive by trial and error and after a million times, the car knows how to make a turn and stop for a red traffic light. — I know this is oversimplified, but you get the point.
A lesser-known application of reinforcement learning can be found in the trading world. Most of us are familiar with applying machine learning models to time series data. At Vesper, we do this to predict various agricultural commodities’ prices, production and stock levels for some months into the future. While these models can indicate where the market is going, they can not tell you what action to take based on their outcome — reinforcement learning agents can tell you when to sell, buy or hold your assets based on how the market is behaving. While applications like this are getting more popular in the stock and forex markets, no cases can yet be found applied to commodity markets.
Together with Slimmer.AI, we (Vesper’s Data Science team) spent three months researching and developing an RL agent that learns how to trade on the commodity market. Read more about these R&D cycles here!
This article will give an overview of our most important findings. We will start with briefly explaining the concept of reinforcement learning, followed by the definition of a trading agent and the benefits of using one. Finally, we will discuss three different reinforcement learning methods and their corresponding pros and cons.
A more in-depth article on the specifications of our agents and their achievements, as well as an introduction to the library used, can be found here. The corresponding git repository can be found here. But if you are relatively new to the concept, please read along!
What is Reinforcement Learning?
Simply said, reinforcement learning is the practice of learning by trial and error. The model learns by being rewarded for good decisions and penalised for bad decisions. This is done by adjusting the size of a reward, called the reinforcement signal, which is either positive or negative and always a consequence of an action taken by the agent.
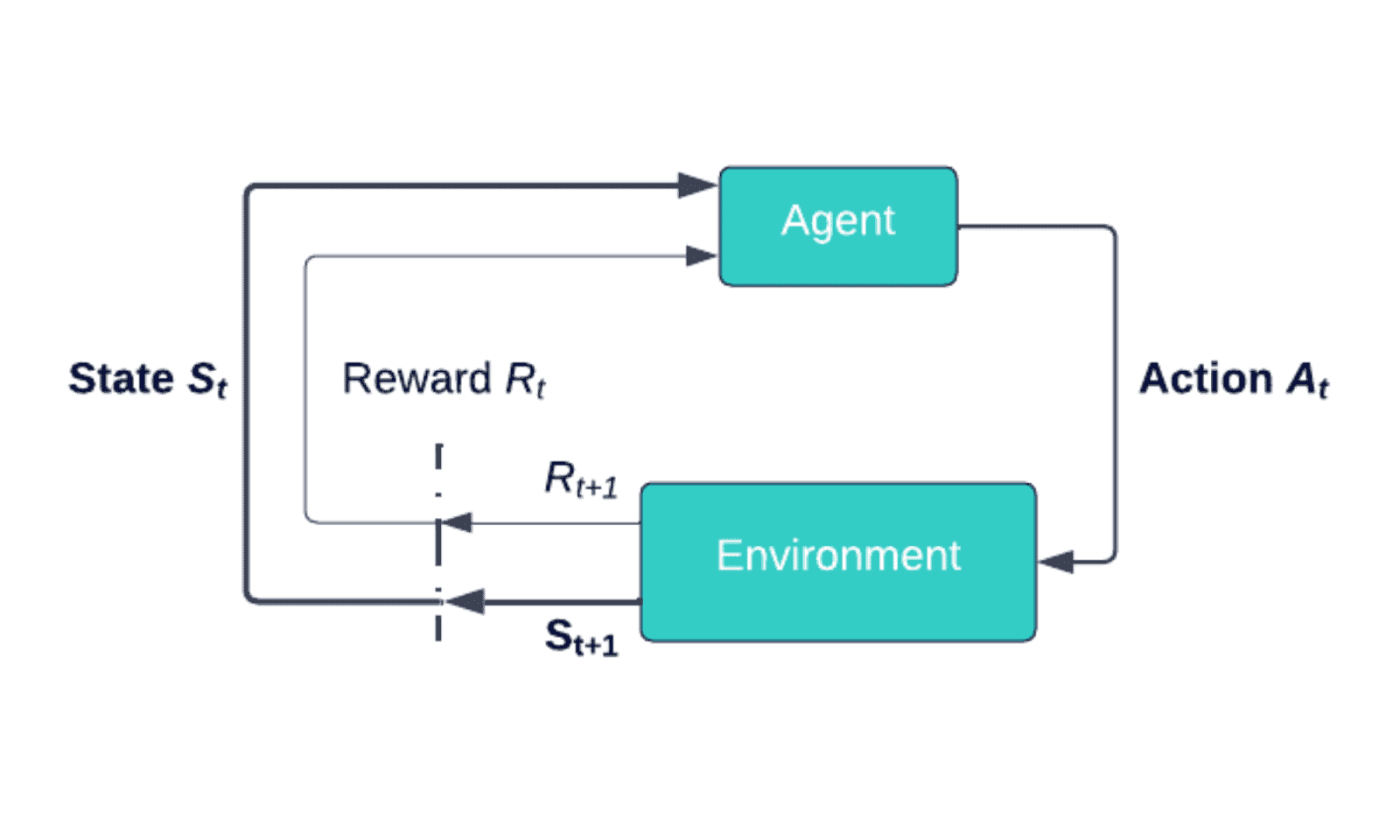
A reinforcement learning model connects an agent to an environment through an action. An visualisation of this is shown in the figure below. The agent is given information about the current state (St,) of the environment. Based on this information, the agent decides on an action (At), changing the state of the environment to St+1. The action is chosen from the action space.
Action-space: The collection of all the actions that are available to the agent that it can use to interact and change its environment
The reward or punishment of the state transition is communicated to the agent through the reward signal (Rt). The system aims to learn an action strategy that finds the environment’s highest cumulative reward value.
A simplified example of a real-life reinforcement learning task is a child learning to walk: The child is the agent who is trying to navigate through the environment by taking actions in the form of walking or crawling. When some steps are taken, the child receives a favourable reaction from the parents, which is analogous to the reward. In contrast, the child will not receive any reaction when crawling or not moving which represents a negative rewards or punishment.
What are Trading Agents?
In the context of trading, a reinforcement learning agent is a trader whose action space consists of buying, selling or holding an asset. The market the asset is part of will act as the environment. The state can be displayed in the form of statistics about the current market, such as daily moving averages, daily highs and lows or asset trading volumes. The reward in trading can be expressed in terms of profit, losses or other performance metrics. Ultimately, the trading agent’s objective is to act in such a way that it maximises the future reward, given the market in which it operates. A good agent should be able to beat the market by buying at low price levels and selling at higher price levels. The agent’s behaviour will largely depend on the RL method chosen. Three commonly used methods are discussed in the last section, but we will first quickly go over the benefits of using trading agents.
Why use trading agents?
Automated trading, also known as algorithmic trading, involves the usage of algorithms for the execution of trade orders, which is the domain trading agents fall under. This form of trading has many advantages over human (manual) trading. First, a distinction should be made between two types of automated trading:
1. Rule-based automated trading, where the strategy is predefined and designed by a human.
2. Reinforcement learning-based automated trading, where the strategy is learned using reinforcement learning.
Both methods benefit from the general perks of using automated trading. While there are many benefits, the most important are the following:
– Computers have fast execution times, which reduces the risk of missing an opportunity due to a slow reaction to the market’s state.
– When using automated trading, you are not exposed to the risk of making poor trading decisions due to emotional and psychological impacts, something that humans suffer from massively. Computers will always execute the strategy they were designed to execute.
– Automated trading benefits from the fact that computers are significantly more capable than human brains in digesting massive amounts of data in real time, allowing for much more complex strategies.
When we look at the benefits specifically for trading agents using reinforcement learning, we can add the following key benefit:
– A trading agent never stops learning and adapting its strategy. A strategy that was once profitable might not work when the market dynamics change. A well-designed reinforcement learning trading agent should be able to adjust his strategy accordingly.
What method to choose for reinforcement learning trading agents?
As mentioned earlier, there are different methods to build a reinforcement learning agent. There are three approaches to use when dealing with financial trading: critic-only, actor-only and actor-critic. Critic-only, the most used method in the automated trading domain, works by solving a discrete action space in the form of a Q-value function.
Q-value function: measure of the total expected reward, assuming the agent is in state St and performs action At
Doing this, it learns the strategy that maximises future reward given the current state. The best-known examples are Q-learning and Deep Q-learning. The key drawback of these methods is that they are designed to only deal with discrete and finite action space problems, meaning that the actions an agent can take must be predefined. Hence special techniques must be used to convert it to a continuous space, as in the case of buying or selling different quantities of a product.
The second approach is called actor-only; here, the biggest benefit is that the action space may be continuous since a policy is directly learned in the form of a probability distribution providing a strategy for any given state.
Policy: mapping from some state St to the probabilities of selecting each possible action At given that state
However, the longer training time that is required to obtain the optimal policies can be seen as a downside to this approach.
The third type, the actor-critic framework, combines the two and simultaneously trains two models: the actor, who learns how to get the agent to behave in a certain state, and the critic, who assesses how effective the selected action actually was. Two commonly used actor-critic algorithms are PPO or A2C. While both methods are highly popular when looking at stock trading, there are some differences between the stock and commodity market that should be considered when deciding on our approach.
The biggest difference between the two markets is the amount of available data. A difficulty researchers often run into when applying AI technologies to the commodity market is its lack of transparency and the associated consequence of little available market data. Luckily, as a commodity intelligence platform, collecting this data is our day-to-day business. Vesper’s database contains thousands of data series covering, amongst others, prices, futures and supply and demand data of various agricultural commodities. Another difference to take into account is the nature of the goods traded. Since agricultural commodities are physical by definition, additional constraints have to be taken into account. Think about expiration dates that force traders to sell a product before a certain date.
In this article, we discussed the basics of reinforcement learning, what trading agents are and why they are relevant to be applied to the commodity market. We also discussed the benefits that come with them and what the most suitable reinforcement learning methods are for our use case. If you are interested in the actual implementation of this method, please have a look here, where we show that trading agents significantly outperform a benchmark model.
If you are interested in the commodity market and how we use AI to disrupt it, please subscribe to our publication!


