


Not only does Vesper show real-time information about the commodity market, it also uses machine learning to predict the prices, production and stock levels for different agri commodities (e.g. Dairy, Veg Oil, Sugar). To help its users understand what variables cause the prices, production and stock levels to change, in this article, Vesper researches how causal inference analysis can help quantify the effect of these variables. Additionally, this could help our users understand and anticipate the impact of large unexpected events such as the COVID-19 or the ongoing war in Ukraine.
In general, causal inference can be used to analyse and quantify different causal relationships. Therefore, in this article, we will quantify and compare the causal effects of butter imports, butter exports and butter production on butter prices. This article is built up as follows:
- First, we will go a bit deeper into what causal inference exactly is. - Second, we will discuss the underlying market structure used to find the causal relationship between butter imports, butter exports, butter production and butter prices and how the identification of causal relationships can benefit Vesper users. - Lastly, we will touch upon the machine learning part of causal inference using the Microsoft DoWhy library, including causal inference results.
What Exactly is Causal Inference?
Causal inference is defined as a process that identifies causal relationships between data and estimates the effect of a specific event (Eichler, 2012). To answer questions such as “How would a user rate a particular movie, when exposed to it?” and “What caused the price of this commodity to change?”, the effect of different variables must be measured and compared (Moraffah et al., 2021). As an example, take the recommendation models at Netflix, such as the personalised movie recommendation rows displayed on the home screen of a user. The traditional recommender system tries to answer a simple question: “How would the user rate this movie?”. The problem is that users will watch their favourite movies no matter what the system recommends. Causal inference allows Netflix to analyse and quantify the effect of different movie recommendations, causing a better understanding of its users and increased performance of current recommendation models. From a Vesper perspective, causal inference can be conducted to better understand what causes commodity prices to move in a particular direction, up or down. The results of our commodity causal inference can help our clients anticipate better and quicker when specific market conditions change.
Correlation Does Not Imply Causation!
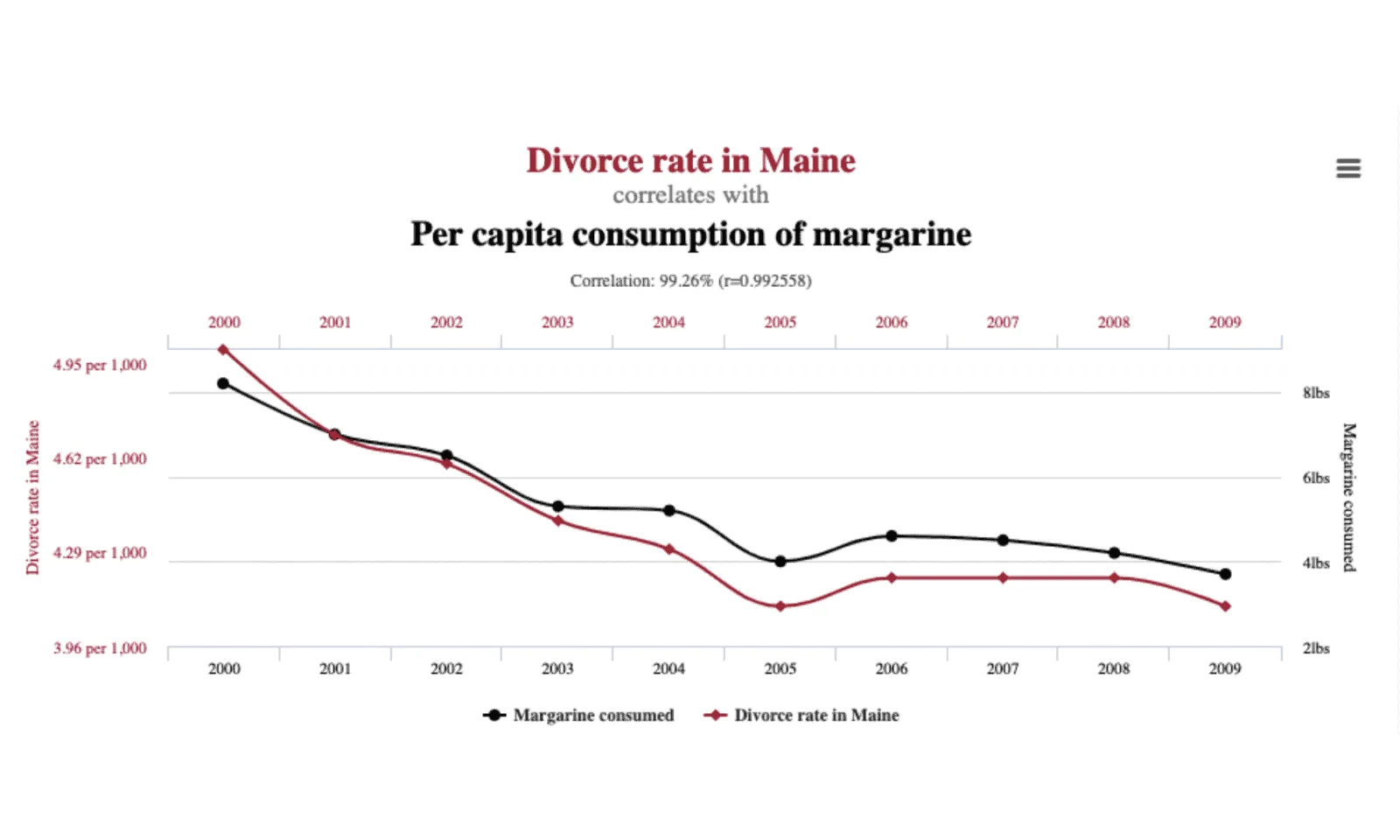
Most of the machine learning models or algorithms that are used for the prediction of stock/commodity prices depend on correlations between variables. However, to get insights into the drivers of the predictions, it is very dangerous to rely on correlation alone. In simple terms, correlation is a measure that describes the size and direction (positive or negative) of the relationship between variables. Looking at correlation alone can make us believe that margarine consumption and divorce rate in Maine have a causal relationship (see figure below). The graph clearly shows that the two events are highly correlated. However, this does not imply that eating less margarine will lead to a more healthy marriage. Correlation is not causation, where causation indicates whether there is a causal relationship between two events and causal inference tests whether a relationship between cause to effect indeed exists.
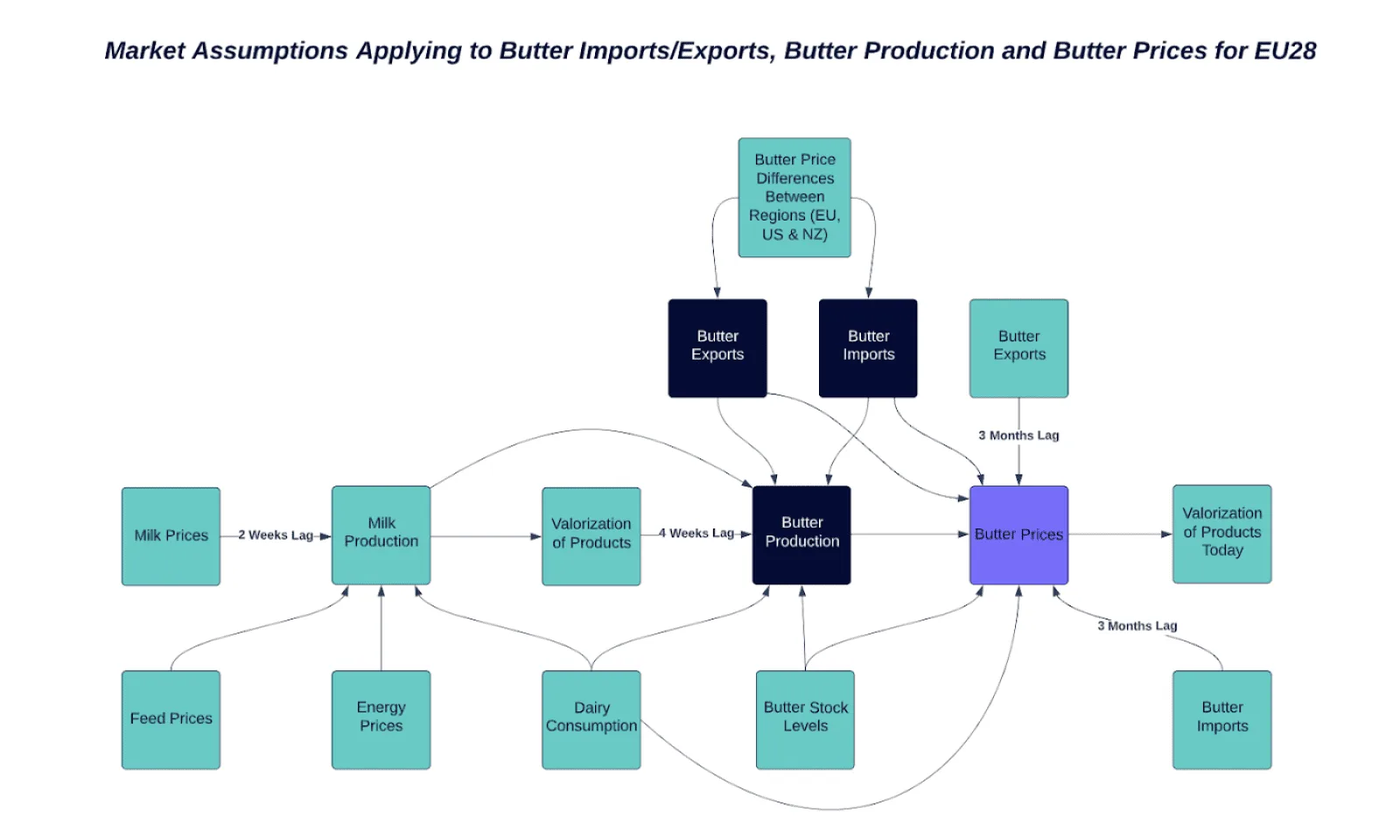
Market Structure
For causal inference, it is necessary to have a clear overview of different factors that affect the butter market. This is done in the form of a causal graph (i.e. a probabilistic graphical model used to encode assumptions about the data-generating process). Market intelligence experts at Vesper created a graph containing all factors that could have an impact on the butter production and butter pricing cycle, which is shown below. The graph displays different relationships between multiple factors, all of which have an (in)direct relationship with butter imports/exports, butter production or butter prices. The butter price is the variable of interest as we conduct causal inference to see the causal effect of butter imports, butter exports and butter production on the butter prices. Arrows in the diagram represent a direct relationship between two variables. As you can see, we assume there is no direct relationship between milk production and butter prices. However, this does not automatically imply that no indirect relationship exists. We can argue that the production of more milk can cause the production of butter to increase due to favourable valorization of products, which indirectly decreases the price of butter. Conducting causal inference, the causal relationship between two or more indirectly related variables can be quantified.
The valorization of products is one of the most important variables. It can be best described as the optimal allocation of resources to generate the highest return possible. Vesper calculates which product, including by-products, is providing the highest return for 10,000L of milk, given the current prices of different dairy commodities. When the prices of butter are extremely high, it is likely that the valorization tool will advise producing more butter as it is more profitable compared to producing other products such as cheese. Therefore, both milk production and valorization impact the production of butter. Butter prices, on the other hand, affect the outcomes of today’s valorization model. Next to the valorization, and therefore the amount of milk flowing into butter production, butter production is also impacted by butter import and export, consumption and stock levels.
Intersection Market Intelligence and Data Science
At a first glance, data science and market intelligence seem to be two different fields of work. The required skills and practical functions vary, whereas the end goal is most often the same; pursuing insights to improve the decisions making within the business or market. To conduct causal inference for commodity prices, we must understand the mechanics of the entire market, as well as have the technical ability to integrate a causal inference model. Market intelligence plays a large role in the creation of the causal graph, identifying all factors contributing to the relationship between two events. In other words, the market structure must be determined before the data science team is able to integrate the causal inference model. Without the required technical skills and/or market knowledge it is almost impossible to understand the results of causal inference for commodity prices. Therefore, a good collaboration between the two different fields is very important, which is something Vesper is all about.
Causal Inference for Vesper Users
Why are we so interested in causal inference at Vesper? It helps us understand the commodities markets better, and create more value for our clients. It allows us to combine the most recent developments in AI with the market expertise of our team. Crucially, automated and quantitative causal reasoning can lead to business intelligence that is more robust, strategic, comprehensive, and flexible. The next part explains the key benefits of causal inference and how it can help our users.
In the last few years, we have learned how heavily impacted business can be by unexpected events. Trade wars, pandemic waves, actual wars, extreme weather conditions, and rising political instability made the supply chains and intricate networks of imports and exports more fragile than ever. Causal inference allows us to prepare our clients for the unexpected. No machine learning algorithm can predict the exact size of the next market disruption. However, we can be better prepared for unexpected events when understanding the effect the variables changed by the event have on the market as a whole. For example, if a major exporter of commodities is forced out of the international market due to sanctions or a trade war, any market prediction based on historic prices becomes obsolete. However, understanding the effect the decrease of export has on the market helps to better understand what the effect of the sanctions will be. Causal inference allows us to use data in combination with our knowledge of the market dynamics to answer questions like ‘What will happen if the import into a given country goes to zero?’, even if that has never happened before. This way, causal inference supplements predictions by providing a more robust and resilient understanding of how the market behaves.
Understanding and estimating causes and effects can help in strategic decision-making. If a company wants to significantly increase the production of a good, it needs to take into account the resulting change in prices. A decision like that is, in general, not accounted for by predictions, as these are based only on historic market data. Sure, that’s probably not an issue for small firms, with limited market impact. But the big players need to know how their actions influence the market as a whole. Causal inference makes this possible. If we know the effect of increased production on market prices, we can better estimate the results of a company’s decision. Thus, by using causal inference models, we can harness the power of AI for corporate planning and strategy.
Lastly, causal inference allows for greater flexibility in planning. It could allow our clients to consider different scenarios, and see how they impact the markets. For example, if there is uncertainty about the weather in upcoming months, a company can check the usual effects of different weather conditions on milk prices, and plan accordingly. Or, if a company believes that its competitor might rapidly increase the import of butter, due to signing a new partnership, it can prepare by estimating the effects this move will have on butter prices. This way, causal analysis can supplement predictions to provide more tailor-made market insights.
DoWhy Package for Causal Inference
To develop a comprehensive causal inference engine, we use an open-source python library by Microsoft: DoWhy (Sharma, Kiciman, 2020). As described by the authors: Much like machine learning libraries have done for prediction, “DoWhy” is a Python library that aims to spark causal thinking and analysis. The library provides a framework to estimate causal effects and conditional causal effects. It combines approaches to causality developed in machine learning, statistics, and economics, which allows for greater flexibility. The library is still in beta but already has an impressive set of functionalities.
The DoWhy approach to causal inference consists of four steps:
- Modelling the problem - Identifying the causal relation - Estimating the relation’s magnitude - Refuting the results
The first step is straightforward — to perform the causal analysis, we need to have a causal graph encoded so the library can parse it. In addition, we need to choose the outcome and treatment variables. In our case: butter prices and butter production.
In the second step, DoWhy uses do-calculus to find the possible confounders: variables that could interfere in the causal relationship between the treatment variable (butter production) and outcome (butter prices). A confounder could be a common cause: for example, the level of butter stock can influence both the production and the prices, so we need to take it into account. Do-calculus is a formal system that, given a causal graph, allows the algorithm to find all such confounders. It has been proven that using do-calculus, the program can always tell if, given the data we have, the causal relation of interest can be identified. Thanks to that, in this step, we can fully rely on the DoWhy library.
The third step, the estimation of causal relation, requires the most work from the programmer. When we know all the variables we need to take into account (control for), we still need to choose a statistical model to estimate the magnitude of this relation. The most popular models include simple linear regression, shrinkage regressions such as LASSO (Tibshirani, 1996) or Ridge (Hoerl, Kennard, 1970), double machine learning models (Chernozhukov et al, 2016), and causal forests (Wager, Athey, 2018). The last two allow us not only to estimate the mean causal effect, but also the causal effect conditional on the value of some other variable. For example, what is the expected impact of producing more butter on the butter price for different levels of butter stocks? This step is similar to the usual prediction exercise, familiar to all machine learning engineers and data scientists. Thanks to that, the skills already developed for predictions can be reused for implementing causal inference tools.
Lastly, DoWhy integrates a comprehensive tool for checking and refuting causal estimates. For example, you can add a random confounder to the model, and see if the results are robust. Thanks to that, you can ensure that the results you obtained are valid, solid, and sure. DoWhy makes the development of our causal inference tools easier and faster. Allowing us to provide better, more comprehensive, and flexible insights into the commodities market.
Causal Inference Results
We use the market structure graph to estimate the causal effects of butter production, import and export on butter prices. It is reasonable to expect that production and import decrease prices while export increases them. However, this is not enough. For precise and well-informed decision-making, it is necessary to know the size of these effects. Does import decrease prices more than production does? Are the effects of import and export on prices similar in magnitude? To answer these questions, we need high-quality data and causal inference.
We estimate that the production of one additional tonne of butter decreases the price of a tonne of butter by 0.0046 euro. That means, producing 1000t of butter reduces the price by 4.6 euros. The effect of import has the same direction but is way larger. Importing 1000t of butter decreases the price of a tonne of butter by as much as 16.8 euros. Exporting 1000t of butter, on the other hand, increases the price of a tonne of butter by 6.2 euros. The effects work in the expected direction and are substantial and significant. Out of these, import has the most substantial effect, way greater than export and production.
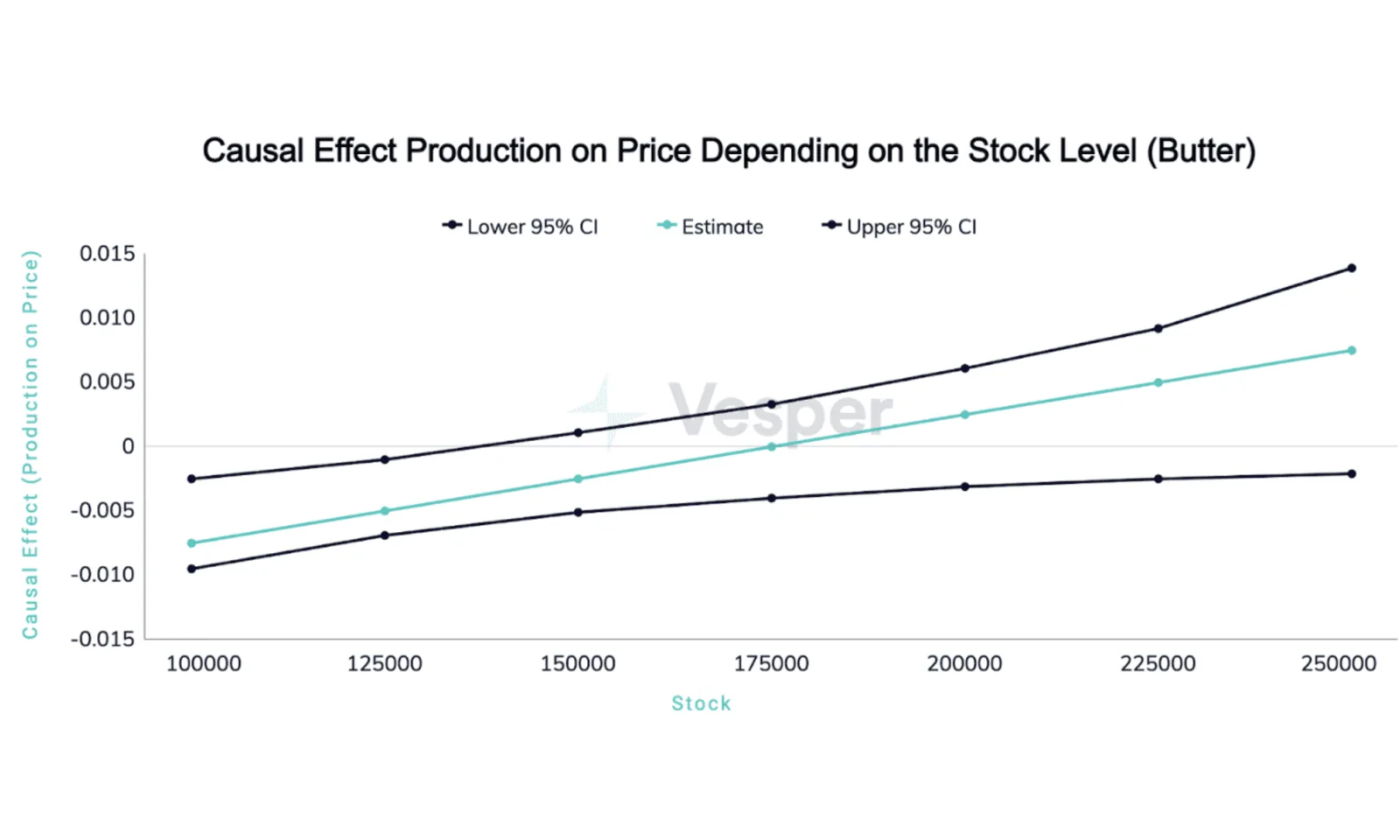
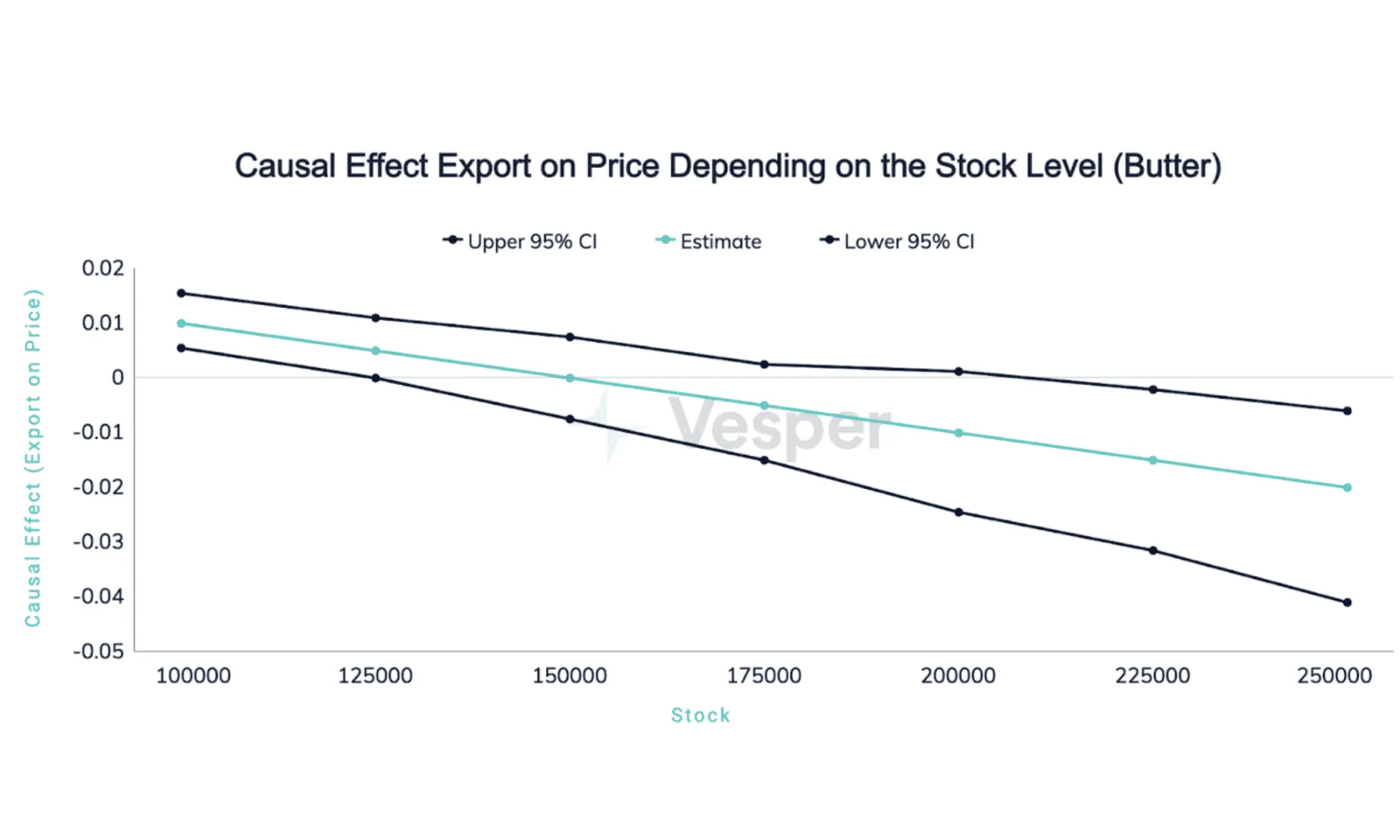
The causal inference engine at Vesper also allows us to estimate the expected causal effects conditional on other variables. We know the average effects of butter production, but how does it depend on the level of existing butter stock? To answer this question, we estimate and plot a model with heterogeneous causal effects depending on butter stocks for all three factors we are interested in: production, import and export of butter.
The effects of butter production on prices are most pronounced and significant for low levels of butter stock. If the stock is below 100,000t, the effect of producing an additional 1000t of butter can be as high as 7 euro. The effects become smaller for higher levels of butter stock and are statistically indistinguishable from zero for stock levels above 150,000t. This shows that a large level of butter stock can have a smoothing effect on the market, reducing any immediate effects of additional production.
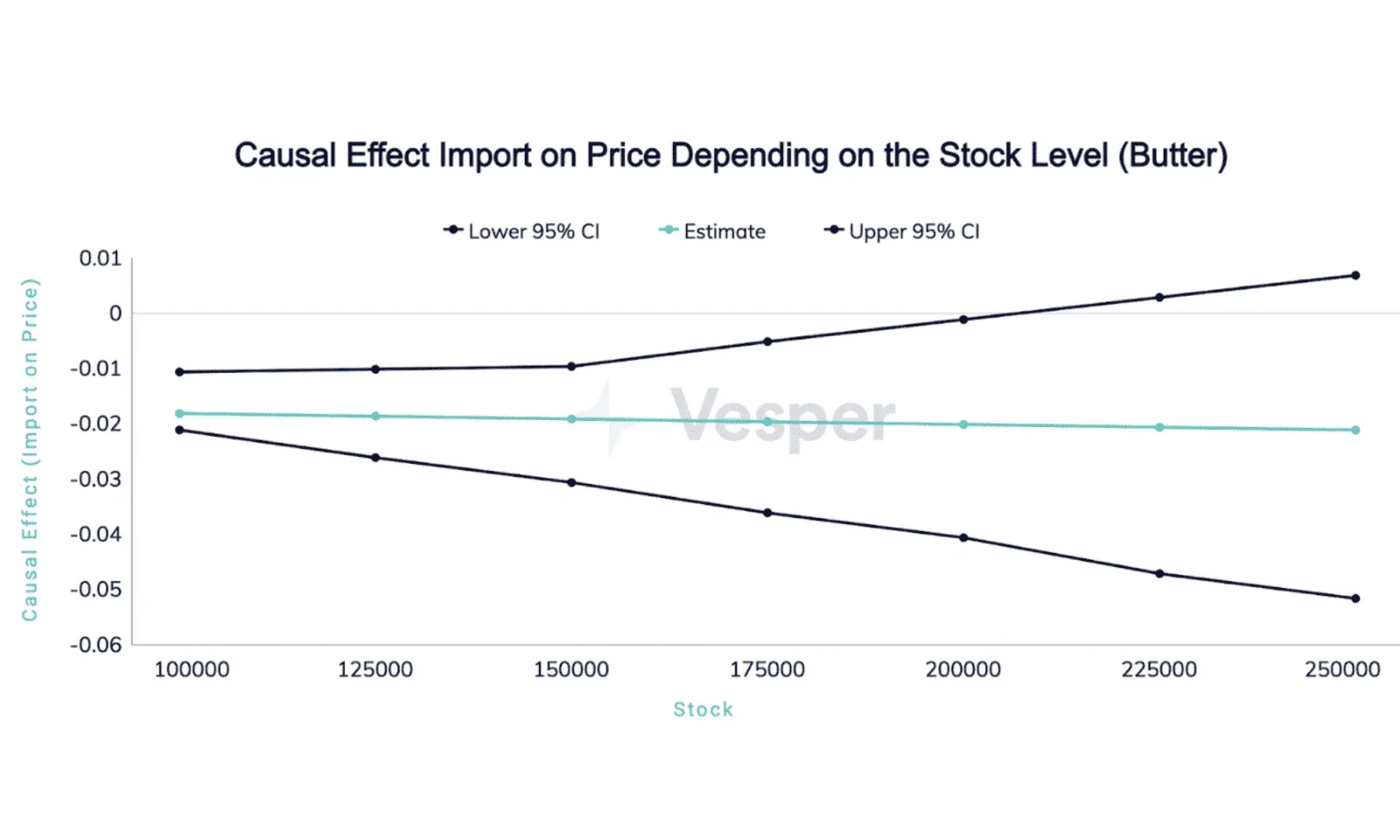
We see a different story in the case of butter imports. The causal effect of importing more butter does not depend on the level of butter stock, and the slightly visible trend is not statistically significant. Importing more butter has strong, negative effects on prices no matter the stock, although the estimated effects in 0.003case of high stock level are quite imprecise.
Lastly, the effects of export are, similarly to the effects of production, sensitive to the stock level. The largest positive effects on prices are visible when the stock is small. Then, exporting 1000t of butter can increase the price per tonne by as much as 14 euros. This effect decreases sharply and becomes insignificant for stock levels higher than 140,000t. This shows that export has a real impact on prices only when butter is not too abundant. For very high levels of stock, export becomes a necessity rather than a strategy, and its causal impact on prices fades.
Key Takeaways
Above mentioned insights help buyers, sellers and traders in the agri commodity market make more informed decisions. Do you find these insights useful and would you like to know what else Vesper can offer, please book a demo with Yannick Aink: Yannick@vespertool.com.
References
Eichler, Michael. Causal inference in time series analysis. na, 2012.Moraffah, Raha, et al. “Causal inference for time series analysis: Problems, methods and evaluation.” Knowledge and Information Systems (2021): 1–45.Blog, Netflix Technology. “A Survey of Causal Inference Applications at Netflix.” Medium, Netflix TechBlog, 6 June 2022, https://netflixtechblog.com/a-survey-of-causal-inference-applications-at-netflix-b62d25175e6f.Amit Sharma, Emre Kiciman. DoWhy: An End-to-End Library for Causal Inference. 2020. https://arxiv.org/abs/2011.04216Tibshirani, Robert. “Regression shrinkage and selection via the lasso.” Journal of the Royal Statistical Society: Series B (Methodological) 58.1 (1996): 267–288.Hoerl, Arthur E., and Robert W. Kennard. “Ridge regression: Biased estimation for nonorthogonal problems.” Technometrics 12.1 (1970): 55–67.Chernozhukov, Victor, et al. “Double/debiased machine learning for treatment and causal parameters.” arXiv preprint arXiv:1608.00060 (2016).Wager, Stefan, and Susan Athey. “Estimation and inference of heterogeneous treatment effects using random forests.” Journal of the American Statistical Association 113.523 (2018): 1228–1242. 18
Go to medium.com/vespertool, for more articles on Data Science and Development at Vesper.


