

For years, commodity buyers, sellers, traders and analysts had to rely on fragmented data sources, making it difficult to keep up with market changes and make timely decisions. Without a central hub of reliable information, professionals often spent hours piecing together data to stay informed and make forecasts.
Today, commodity intelligence platforms like Vesper solve this problem by offering a one-stop solution, bringing all essential pricing data, market reports, and forecasts into a single, easy-to-access place.
Yet, as helpful as these platforms are, they’re also packed with powerful tools and information, which can be overwhelming to navigate. Users often face challenges like determining the exact product they need (e.g., navigating through 17 different types of flour) or understanding how to interpret our forecasting tools to aid in budgeting decisions.
Vesper’s mission is to remain the most user-friendly commodity intelligence platform on the market, continually enhancing accessibility and ease of use. As part of this commitment, we’ve introduced Vesbot—an AI-powered chatbot that provides instant answers and guidance without interrupting workflow.
Built using ChatGPT models tailored specifically to Vesper’s data and use cases, Vesbot quickly connects users with relevant insights, guides them through the platform’s features, and provides contextual assistance for complex decisions. Vesbot streamlines the user experience by reducing the time spent searching for answers and offers support around the clock, enabling users to make faster, more informed decisions and fully leverage Vesper’s capabilities.
With Vesbot, users can seamlessly access Vesper’s full range of insights and data without the friction of navigating a large platform or waiting for human support—bringing commodity intelligence to new levels of accessibility and efficiency.
In this article, you’ll discover the journey behind building Vesbot, including the technical approach we chose, the challenges we encountered, and the future developments we’re planning. By the end, you’ll have a deeper understanding of how Vesbot works, the AI innovations that power it, and how it’s designed to provide faster, smarter insights for our users.
How did we approach building a custom chatbot?
So why did we start this project and how did we tackle this? I’m sure many of you are already familiar with ChatGPT. This chatbot, which is essentially an AI model paired with a user interface, is incredible at providing answers in a way that feels very human-like. However, addressing questions specific to your use case can be challenging. This is because it lacks the necessary information to fully understand your question. To achieve this capability, the model would need to be familiar with data related to that specific use case.
There are several methods for customising a chatbot to address specific use cases. We explored various options, including training the chatbot with a predefined set of questions and answers or using rule-based systems for specific scenarios. Ultimately, we selected the Retrieval-Augmented Generation (RAG) approach.
RAG stands out because it enables the chatbot to access and retrieve information from a vast database in real-time, ensuring that responses are always up-to-date. This approach allows the chatbot to pull in the most relevant data to answer questions accurately. Additionally, RAG enhances the chatbot’s ability to provide contextually appropriate responses while giving us the flexibility to tailor it with data and insights specific to your unique needs.
Large Language Models and Their Adaptation
In this chapter, I will introduce some key technical concepts that are fundamental to understanding RAG systems. If you’re already familiar with these concepts, feel free to skip ahead to the “How Does RAG Work?” section.
Large Language Models (LLMs)
LLMs are often based on transformer architectures, meaning they take input, encode it, and then decode it to generate output, just like other transformer-based models. The key difference between LLMs and regular transformers is their training on extremely large datasets, including sources like websites, books, research papers, and more. This extensive training allows LLMs to develop a deep understanding of language.
Think of an LLM as a super learner who reads billions of sentences to understand language in the same way humans do, including context and cultural hints. It learns by itself from vast amounts of written material without anyone having to teach it explicitly. This self-learning capability is what makes LLMs so useful in various settings, such as powering chatbots.
LLMs are incredibly versatile and can be applied to any project involving text. For instance, they can analyse the tone of a news article to determine whether it’s positive or negative. We use LLMs to create chatbots that can chat naturally, providing more intuitive and human-like responses in conversations.
Prompting
We can describe prompting as a way of communicating with an LLM. By giving it a set of instructions, you can tailor the LLM to suit your specific use cases. The quality of the prompt is crucial because the more effectively the instruction, the better the answer you get. Imagine you’re asking ChatGPT a question, but the response you get isn’t quite what you were hoping for. You might rephrase the question, add more context, or specify certain details. This process of refining your input is essentially prompt engineering.
Fine-tuning
Fine-tuning is when we teach a pre-trained model to perform better on a specific task. For LLMs, this involves using a supervised learning method, where the model is trained with a labelled dataset. For example, if you’re fine-tuning an LLM for sentiment analysis, you’d use a dataset where each text is marked as “positive” or “negative”. During fine-tuning, the model adjusts its internal settings to improve at predicting the labels correctly. This process customizes the LLM, enhancing its accuracy for your specific project. Fine-tuning makes the model perform better for your particular application than it would in its original form.
RAG
Now that you understand the concepts of LLMs, prompting and fine-tuning, let’s talk about the method we have chosen for our application: RAG.
Simply put, RAG is a technique that allows you to add your own data to an LLM so it can generate more accurate and relevant responses. This method addresses two major challenges commonly faced by LLMs: hallucinations and outdated information.
Hallucinations occur when an LLM generates incorrect information, often because it doesn’t know the answer but tries to provide one anyway. Outdated information is an issue since LLMs are trained on data available up to the date of training, thus lacking the most up-to-date information.
Since we are building a chatbot, providing users with current and correct information is essential. Outdated or incorrect responses can erode trust and diminish the effectiveness of the application.
By using RAG, we can mitigate these issues. The model retrieves relevant information from a specific, up-to-date dataset and combines it with its language generation capabilities, ensuring that the responses are both accurate and current.
Next, I’ll explain a little more about how RAG works and the steps required to implement it effectively.
How does RAG work?
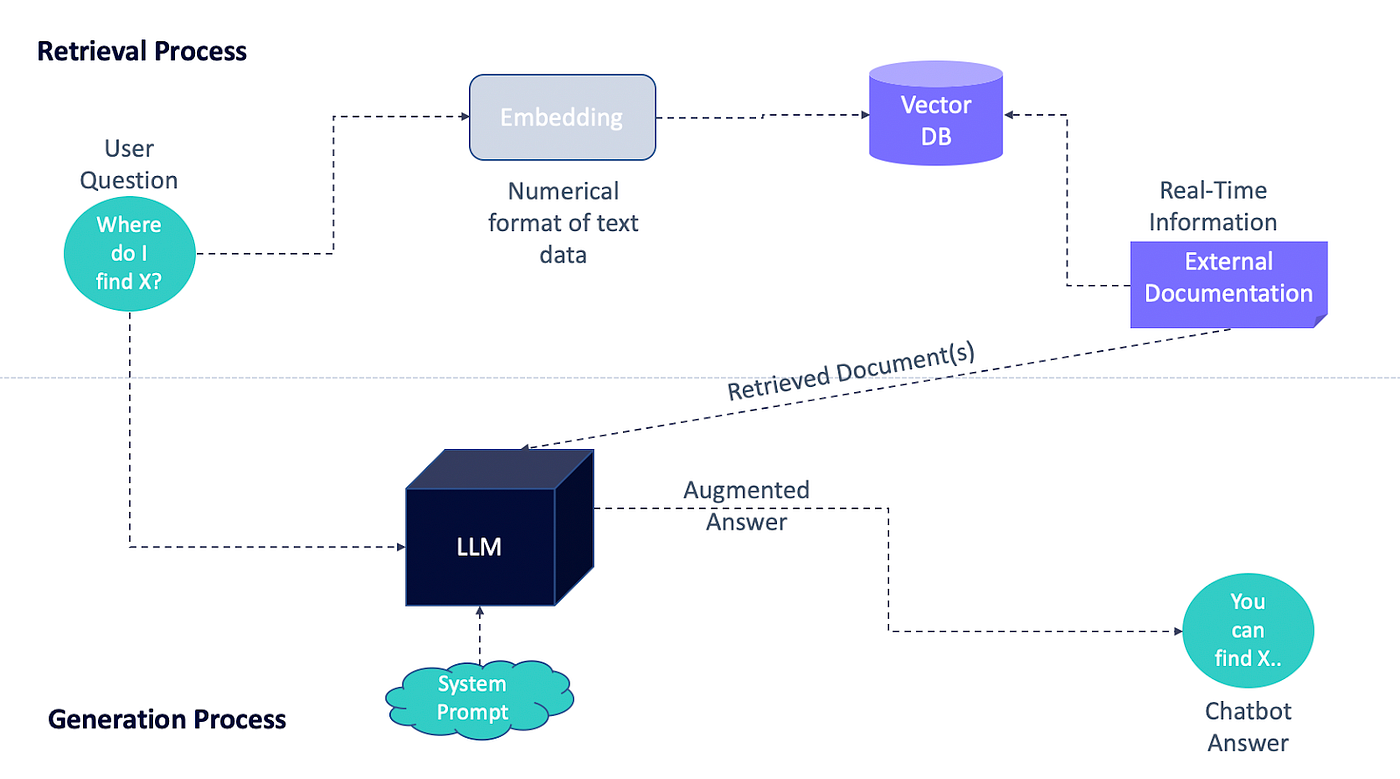
To fully grasp how RAG allows LLMs to produce more accurate and contextually relevant responses, we need to explore three essential components: external documentation, the retrieval process, and the generation phase. The image above illustrates these concepts in detail.
External Documentation
LLMs are trained on large datasets, but they do not include specific or up-to-date information beyond their original training data. External data, which can come in various formats like structured databases, PDFs, or plain text documents, needs to be incorporated into the model’s knowledge base. To do this, external data is converted into a numeric format and stored in vector databases, making it accessible and interpretable by the LLM.
Retrieval
Once we have stored our external data in a vector database, the next step is the retrieval process. Our external data contains many different documents, and the goal of retrieval is to return only the parts related to the user’s query from these documents. In this process, the most relevant documents are returned using a relevancy score, which is based on how closely the query matches the content of the documents.
For example, if a user asks a question like ‘I want to make changes to my account’ to the FAQ chatbot, the retrieval system searches through the data to find documents related to account management. Additionally, the algorithm might prioritize documents that specifically address common account changes or procedures, ensuring the user gets the most relevant and helpful information.
Augmentation
Once the relevant documents are retrieved, the LLM uses this data along with any given prompt, to generate a response. In this step, the prompt plays a crucial role. As mentioned before, a well-crafted prompt can significantly influence the LLM to produce a response that aligns with your expectations. With the combination of accurate external data and a carefully designed prompt, RAG ensures that the LLM can provide a precise and contextually relevant answer.
The importance of high-quality documentation
The effectiveness of our help and support chatbot is rooted in the quality and organisation of the information we provide to the RAG system. By carefully curating and structuring these documents, we ensure that the chatbot can deliver precise and helpful responses to user inquiries.
To maximise the chatbot’s utility, we have organised the data into distinct sections. Given that this is a chatbot tailored for the Vesper platform, it is essential to include comprehensive documentation relevant to the platform’s various features and functions. We included the following types of documents:
Platform Navigation and Structure:
- Purpose: To assist users in navigating the Vesper platform with ease.
- Content: Detailed descriptions of the platform’s structure, including how to access different sections and use various features. This also includes product guides that provide step-by-step instructions for using specific parts of the tool.
Functionality Documentation:
- Purpose: To provide quick and accurate answers regarding the platform’s specific functionalities.
- Content: Information on advanced features such as data downloading and API integrations.
Market Reports and Regional Insights:
- Purpose: To provide insights into what types of analysis we cover across various commodities.
- Content: Explanations of reports on various commodities, with their relevance and usage within the platform.
Data Availability:
- Purpose: To inform users about the available data series on the Vesper platform.
- Content: A comprehensive list of available data on the platform.
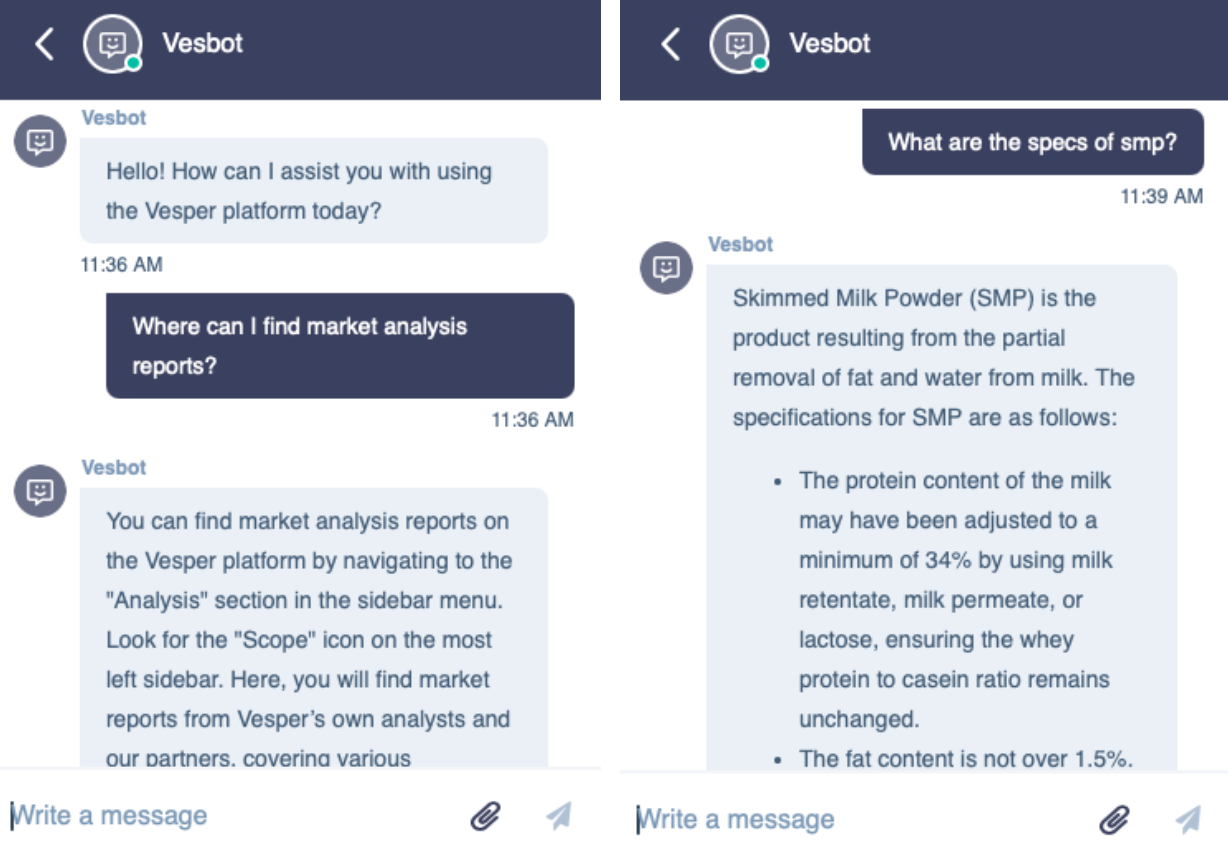
Using this data, the following examples show you how the chatbot is now able to support our users with very specific platform-related questions:
The Importance of External Data Quality
Throughout the development of the chatbot, we encountered challenges related to the quality and structure of the documents. High-quality, well-organised documents are crucial because they directly impact the chatbot’s ability to retrieve and deliver accurate information. Poorly structured or outdated documents can lead to irrelevant or incorrect responses, which could diminish user trust in the system, and in the worst-case scenario, do more harm than good.
To address this, we ensured that all documents were well-organised and regularly updated. This not only improves the retrieval process but also ensures that users receive the most current and accurate information possible. As we continue to expand the chatbot’s capabilities, maintaining the quality and relevance of these documents remains a top priority.
Future Developments
Our current chatbot works great and will help our users in many ways, but we’re aiming for even better performance. We strive to continually improve the service for our users by analysing their interactions. This way, we can see what kinds of requests are being made and guide our future developments accordingly. For instance, if there are a lot of inquiries about the current state of the market, we can explore ways to better provide market information to our users.
One of our biggest challenges moving forward will be ensuring the chatbot consistently provides up-to-date information. This requires regularly updating its knowledge base with the latest data, especially in fast-changing fields. Our goal is not only to make the chatbot feel like a real conversation partner but also to ensure it always delivers the most current and relevant information. By focusing on these aspects, we aim to offer timely assistance on various topics, ensuring our users receive accurate and helpful responses.
We’re excited to see this chatbot grow into a truly comprehensive assistant that not only answers questions but also delivers market insights, personalized recommendations, and even helps with complex decision-making.
Follow Tuğçe Güneş’ publications, Machine Learning Enginees at Vesper, to stay informed as we continue this development journey!


